Introducing PaperQA3: a frontier multimodal deep research agent for science
Andrew D White, James D Braza, Michael Pieler, Michael Skarlinksi, Siddharth Narayanan
Date:
02.18.2026
We are introducing PaperQA3, a major update to the algorithm that underlies Edison Literature agent and literature search within Kosmos. Among many other improvements, PaperQA3 introduces the highest-performance multimodal capabilities available for deep research agents today. As a result, Edison Literature and Kosmos can now read figures and tables from over 150M research papers and patents, and will read, parse, and consider hundreds of figures and tables before responding. This is a major advancement from our previous literature agent, PaperQA2, that could only surface information from the text of research papers. Additionally, we’ve updated the underlying algorithm of our literature agent (which is open source) to improve its ability to answer more complex questions. The result of these improvements show Edison Literature as one of the strongest deep research agents across relevant LABBench2 subsets and two Humanity’s Last Exam variants, beating out current-day frontier deep research agents. The PaperQA3-backed version of Edison Literature is available today on our platform and API as literature-20260216, as is Edison Literature High (literature-20260216-high), a high-effort variant for best performance.
Edison Literature was built with three goals: clear provenance of claims, high accuracy, and concise answers. Edison Literature does not just rely on web searches - we use metadata from many sources to assess the provenance of documents. This allows us to check if a journal is predatory, know the country of origin for a patent, or if a manuscript was retracted. Providing this information to the underlying LLMs mitigates the sycophantic tendency to believe all sources and gives our system more skepticism, similar to an expert scientist. We benchmark all aspects of our agents heavily and believe our systems have the highest current accuracy for questions about scientific literature and clinical trials. Lastly, we find lengthy LLM-written responses to be unsuited to scientific tasks and have designed our systems to give crisp, cited, and clear responses.
The main figure of a research paper is often as valuable to a reader as the entire text. Thus, adding multimodal understanding to Edison Literature is a big step forward. Doing this correctly required iterating on many approaches and careful benchmarking. It’s not as simple as showing all figures from all candidate documents to an LLM, because each unrelated figure has potential to confuse the LLM. Reasoning about figures also complicates retrieval: how do you find the right paper in the first place? Multimodal embeddings seem like an easy answer, but then you have to consider that across millions of documents (our scale) there's edge-case figures with vague detail in the figure itself or poorly-worded captions, degrading embedding space search. One of our main design decisions was, instead of context engineering a text-only or multimodal embedding model's input, we just let the underlying agent LLM choose when to draw upon figures and only then put them into the context.
Another challenge was parsing scientific documents to extract figures, tables, and formulas. Edison Literature is built around ingesting PDFs, as opposed to webpages. Scientific articles are complex documents with multicolumn layouts, extra wide figures, non-standard tables, and equations interspersed amongst text. We evaluated multiple parsers that read documents based on the PDF specification and those built on vision-language models. We found the NVIDIA Nemotron Parse open-weight model to be the best for working with scientific figures. We process hundreds of thousands of pages per day and at a required latency of ten seconds per page. Working with the team at NVIDIA, we were able to scale-up Nemotron Parse to work at this scale using vLLM and NVIDIA H200s, and have written up the integration’s details in this NVIDIA case study: https://developer.nvidia.com/case-studies/scientific-literature-ai-nvidia-nemotron
We evaluated Edison Literature on LABBench2, recently released by Edison Scientific, and Humanity’s Last Exam (HLE). HLE, especially in chemistry and biology questions, is less about reasoning over scientific literature and more about exam-style questions. Nevertheless, it provides an independent benchmark. LABBench2 has a large number of categories for testing AI agents on scientific tasks. Many of them are well-suited for our literature agent, for things like figure understanding, reading clinical trials, and reasoning about patents. Our performance is shown below, along with other frontier LLMs and agents below.
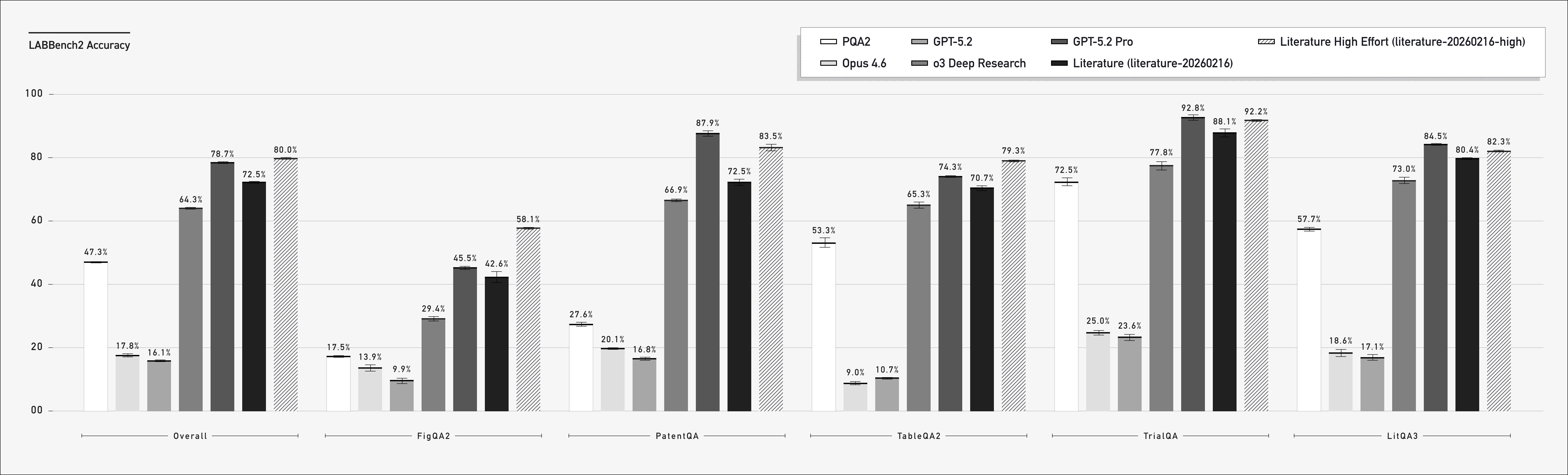
The LABBench2 results show that adding figure understanding has provided a large gain in tasks that require reading figures (FigQA2 and PatentQA) relative to PaperQA2. GPT-5.2-pro is a powerful baseline and does well in tasks that require visiting webpages, like clinical trials and patents. Edison Literature excels when working with figures and tables. Next, let's consider Humanity's Last Exam:

Humanity’s Last Exam (HLE) and HLE Bio/Chem Gold (an expert-verified subset of HLE) are exam-style questions that sometimes require retrieve a scientific source. For example, one HLE question in the biology category asks if snakeflies have ever been observed to eat nectar in the wild. This requires reviewing scientific papers, and possibly knowing that snakeflies are predatory. The broader HLE category is below, which includes multimodal questions as well.

Edison Literature High is the strongest system across LABBench2, Humanity’s Last Exam, and HLE Bio/Chem Gold. Much of the gain comes from its ability to retrieve and view images and tables. There are also significant gains over PaperQA2, whose constrained agentic loop for answer generation is no longer necessary given modern LLMs' ability to call tools with complex inputs over long contexts.
These benchmarks are hard to assess, because most deep research agents being built today focus on web search as the primary tool to retrieve documents. This can create leakage because many of our benchmarks questions and HLE questions are already available and discussed on the internet. Another challenge is that benchmarking LLMs has more to do with their web search tool robustness, rather than their intelligence or reasoning ability. We have done our best to employ retrying and build our benchmarks around open source papers that agents can access, so that we focus on the algorithms and LLMs. However, the numbers reported on LLMs without a web search tool should only be taken as a reference for how easy these questions are for an LLM to reason about without sources, rather than an assessment of their ability to work on scientific tasks. Please see our LABBench2 release which does ablations on providing source documents across multiple frontier LLMs.
Aside from improving the LLMs and adding figures and tables, we made a number of improvements since our most recent PaperQA2 preprint. We have given the underlying LLM agent more autonomy by letting it inspect documents, review chunks, and decide when to answer. We’ve removed the strictness of our harness, so that the LLM agent can determine how and when to finalize an answer. Lastly, we’ve added some niceties like having tables be generated and showing the underlying figures/page-numbers used in citations. The impact of these changes are evident in the universal boost of 15% to 45% accuracy from PQA2 to Literature, shown in Figure 1.
As we now use thinking LLMs for the agent, we can increase the thinking token budget to gain higher accuracy with our agent. Along with other hyperparameter adjustments, this gives about a 7 point gain in accuracy, surpassing OpenAI GPT-5.2 Pro's performance, and is the setting we report above in the benchmarks. We’ve made this version available as a “High Effort” mode in our platform. The normal “Literature” is free if you have a subscription on our platform, or academics get about 20 free calls per day.
To conclude, here is an example showing what you can do with the new version of Edison Literature!
Example: How important are the geometric neural network components of AlphaFold2?
AlphaFold2 was a remarkable achievement for protein structure when it came out in 2021. One of the surprising parts of their neural network was the complexity of the components, including new attention mechanisms and parts of the network that were invariant to rotations and translations. The invariant point attention module (IPA) was considered key for the success and was a major point of discourse, launching a new wave of research on geometric equivariant neural networks. Yet in the paper itself, removing the IPA module didn’t actually have a huge impact on performance. This wasn’t mentioned in the text and required careful reading of Figure 4a.
We can ask Edison Literature this question: “In the alphafold2 paper, how much did removing the IPA module affect the structural prediction accuracy?” Edison Literature finds the original paper about AlphaFold2 and correctly identifies Figure 4a as containing the right information. Then it reads the figure and sees that the impact on performance is relatively modest, except when synergized with the recycling. Then it reads it more carefully, with zoom, to get a quantitative estimate of the effect. Finally, it summarizes the impact as modest, but points out that the IPA enables the recycling (iterative refinement) that is key to the algorithm. You can see the complete response here: platform.edisonscientific.com/trajectories/ad05e3c5-6578-4a62-8488-8e5c28f91bfb